Decisioning: A New Approach to Systems Development (Part 1)

Summary
The term 'decisioning' is in growing use in the business systems lexicon. The concept of 'decisioning' recognizes the fundamental importance of decision making to any business. Decision-making know-how is the critical knowledge that differentiates one business from another in the marketplace. This paper provides insight into decisioning as a new and critical driver of the Systems Development Life Cycle, as drawn from the author's many 'decision centric' development experiences. For context, we first present background and definitions for decisioning and then outline practical approaches and techniques for decision-centric development.
The new approach recognizes that decision automation is a key motivation for many systems development projects, particularly where 'zero touch processing' is important. Enormous effort is invested in discovering and elaborating decision-making know-how as part of the development process. Typically, this know-how has then been 'deconstructed' into an amorphous code base so that the integrity and identity of the decisioning knowledge is lost.
The decision-centric development approach inverts the traditional design approach so that decision-making know-how is acknowledged as a primary design artifact of the system. Data and process then become supporting players, which in turn drive technology development. The integrity and identity of decisioning is retained so that it can be directly owned and managed by the business on an ongoing basis.
Building on these decisioning fundamentals we suggest that decisioning is the primary driver of (non-commodity) product development and management. What decisions a business makes in support of product selection, pricing, approval, and terms and conditions is the key characteristic that differentiates one business from another. Developing this concept, we present a case for a new product development cycle based on decision-centric product engineering.
Using this approach it is practical to build systems that become containers for products, with the products themselves being built externally and submitted to the container for execution. Product configuration can be a reality.
Introduction
Our journey towards a new development paradigm -- and why you should not have programmers doing your business rules.
The discovery and normalization of data is a proven and accepted design approach that underpins systems design activity. Similarly, various approaches to process discovery and decomposition can be used to drive a process centric design approach.
These primary design approaches have evolved over decades, and while each has their adherents, both are mature and give rise to formally structured models.
This article proposes that we add a new primary design artifact to this select group -- the decision. Like both data and process, decisions can be the subject of original discovery and can drive further design activity. In fact, decision modeling takes precedence over process modeling as a primary design tool. Processes only exist to service either data (collect, modify and/or distribute) or decisions; without data or decision-making activity, there is no process requirement.
A further purpose is to discuss methods by which decisions can be discovered and modeled in a structured manner, analogous to data normalization. Data and decisioning are peers in this decision-centric approach -- each showing a different and complementary view of the same system. Data models show the valid states of the system at rest; decisioning models describe the valid transitions between the states. It is the state change as described by the decision models that generates value for any business.
Then we introduce a powerful new business approach that leverages the hidden power of decisioning. This approach, 'product engineering', builds on the fact that decisioning is the core element of product definition and management -- decisioning is the key differentiator of vendor products.
Note: In this discussion we will generally use the insurance industry for examples, but virtually any productive enterprise provides a wealth of examples. Decisioning is pervasive across all industries.
What is Decisioning?
Decisions are the critical mechanisms by which we choose one action from the set of all possible actions. The purpose of a decision is to select the action that is most beneficial to the decision maker in a given situation. A decision is 'made' when we resolve the available facts to a single definitive outcome; a decision cannot be multi-valued, ambiguous or tentative. A decision results from applying discipline, knowledge, and experience to the facts within the decision context. This application of discipline, knowledge, and experience within decision making is the characteristic that most closely defines the unique character of any business.
Definition - Decision: the result of applying structured business knowledge to relevant facts to definitively determine an optimal course of action for the business.
Recognizing the power of decisions to regulate and control system responses in a zero touch processing environment is driving increasing interest in decision automation.
Businesses do not make decisions merely because they have available data; nor do they act without making a decision. Decisions are clearly identifiable at the heart of any automated systems response, giving purpose to the data and direction to the process.
When decisioning approaches are used in the early requirements design of systems, they can be used to drive the discovery of data and its relevance to the business -- the need for the decision drives the need for the data. And because the decision predicates any process response, it also implicitly drives the process definition.
Decisions are also drivers for the discovery of other decisions. For instance, the decision to accept insurance business depends on precursor decisions regarding the customer, the insured risk, pricing, etc. Each additional decision can also depend on further decisions until a tree structured model of decisions is formed (the 'decision model').
Our experience suggests that decisions are the easiest of the primary design elements to discover and model, because decisions are the core of business knowledge and are intuitive 'first order' knowledge for domain experts in a way that both data and process are not. When the decision model is used to fast-track the discovery and modelling of both data and processes, it gives rise to a 'decision oriented' system -- a system that has business decision making as its core architectural consideration.
Definition - Decisioning: the systematic discovery, definition, and management of decisions for the purpose of decision automation.
We have asserted that decisions are first order citizens of the requirements domain. To provide a conceptual basis for this, let us go back to the beginning of any requirements analysis.
A business derives value from changing the state of a recognized business object. This focuses us on the very core of the business -- what is traded, managed, leveraged, used, built, or sold in order to achieve the objectives of the business. Until something happens to the object, the purpose cannot be achieved and no value can be derived; therefore, in order to generate value, we must have a state change on the object. Note that we are interested only in the objects that are the basis of value and which are fundamental to the purpose of the business. We are not interested in data entities per se, including such traditionally important entities as customer (we do not generally derive value from changing the state of customers).
Changing state implies that there is activity against an object, and this observation gives rise to the traditional process (activity) and data (object) approaches.
But if we look closely at any process causing state change, we will see that the change is always the result of a decision within the process rather than the process itself. Many processes can execute against the object, but value is only derived when a state change occurs. Whenever state change occurs, the process can be shown to be a container for decisioning -- the state change is a result of the decision rather than an inherent characteristic of process. Confusion between decision and process clouds the issue and hides the importance of decisioning -- to the extent, for instance, that UML does not include decisioning within the UML standard.[1]
Processes are merely mechanisms by which data is supplied to a decision, and by which the systems respond to the decisions made. If these pre- and post-decision activities are wrapped together with the decisioning logic, then we have a complete end-to-end process that takes the business from one valid state to another, and which generates value in doing so. But it is clear that the entire process is built around the decisioning kernel. We know customers who supply decision content for third party processes -- the commercial supply of decisioning and process by different parties emphasizes the distinct and separate existence of both decision and process.
Our arguments so far suggest that data and process both exist to serve decisioning in the same way that memory and peripherals exist to serve the CPU in a computer -- each has a futile purpose without the decisioning requirement or the analogous CPU respectively.
Traditional Approaches
We have argued that decisioning is the root of the enterprise (its 'CPU') and that decision designs are tangible IP assets. Decisions should be catalogued and managed like any other important IP asset, visible to and operable by the business as required. Decisioning knowledge should not be 'deconstructed' into an amorphous code base, as often occurs in traditional development models.
The traditional practice for implementing decisioning logic has been to encode it within the application, using the same programming language as used to implement the technical aspects of the application. The decisioning becomes intertwined with other aspects of the application, including persistence, user interface and integration logic. This causes several problems:
- Verifiability: Decisions implemented in a standard programming language
(e.g. Java, C#, C++) are difficult for non-technical users to understand.
It is therefore difficult to verify that the implementation of the decision matches
the requirement.
- Maintainability: Implementing the decisioning as part of the core application
logic increases the complexity of the application. This makes it difficult
to vary one aspect without affecting others, which in turn makes it difficult to
maintain the application.
- Risk, Cost, and Time: These factors increase exponentially
with overall system size.[2]
By segmenting out the decisioning, we reduce the overall problem into smaller,
simpler problems and thereby reduce all three factors.
- Redundancy and Overlap: As systems evolve and adapt to new requirements,
decisioning rules are duplicated to cater for the new requirements. This can
result in multiple implementations of logic for one business decision.
- Misplaced Context: Programmers often disperse decision logic into pre-existing
designs -- usually architected around functional or technical requirements -- whereas
a decisioning viewpoint would say that the state change of the object is always the
relevant context. These differing viewpoints lead to different architectural
designs.
- Documentation: As systems evolve, it is normal for external decision documentation to become 'out of date'. The implementation becomes the repository of the decision logic, and it can be difficult to reliably reverse engineer the decisioning from the implementation.
These problems, caused by implementing decisioning within the application using a standard programming language, are not resolved by modern object-oriented design methods. Object-orientation is good for managing the complexity of an application by abstracting and encapsulating data, and the functions that operate on that data, inside classes. However, a decision typically requires the participation of more than one business object, which can mean that the decisions become fragmented into multiple classes.
A similar problem occurs when implementing business rules in relational database management systems (RDBMS). Typical RDBMS-stored procedure languages are data-oriented, so decisions again tend to be fragmented across the participating data. Further, the heavy use of triggers to implement decisions can seriously impact the maintainability and comprehensibility of decisioning.
This 'deconstruction' of decisioning into the code base of a traditionally designed system occurs because the decisioning components do not have their own natural 'model' architected into the system.
Decisioning models do not map directly to the data, process or object models that are the models recognized in traditional approaches, so decisioning is 'forced' to fit. The forced fit is unnatural and causes the fragmentation of decision logic and/or its placement out of context.
The problem originates early in the Systems Development Life Cycle (SDLC); in fact, every step from requirements to implementation adds to the problem. The separate identity and integrity of decisioning behavior, which is usually well understood by the business sources, is progressively lost as it is translated and diluted at each step in the SDLC:
- The original requirement is (still) usually captured in English narrative form
from a variety of sources. The narrative form introduces ambiguity, personal
phrasing and interpretation, and not uncommonly, outright logical conflict.
The identity of decisions is rarely retained, to the extent that any narrative requirements
specification creates its own need for downstream analysis of the narrative.
- The narrative is then translated into structured design documents (data models,
process models, use cases, etc) and expanded to include non-functional specifications.
Decision definitions are usually fragmented throughout these documents as
properties of other concepts.
- The design documents are translated into detailed design and program specifications,
further dispersing the decision specifications across the technology layer (security,
communications, platform, and distribution).
- The low-level specifications are translated into program code, and they are expanded to include exception and control processing.
At the end of this process (see Figure 1) the original decisioning requirement is likely to be diffused throughout the code base without traceability to the original requirement.
Figure 1. Systems Development Life Cycle: "The Old Way"
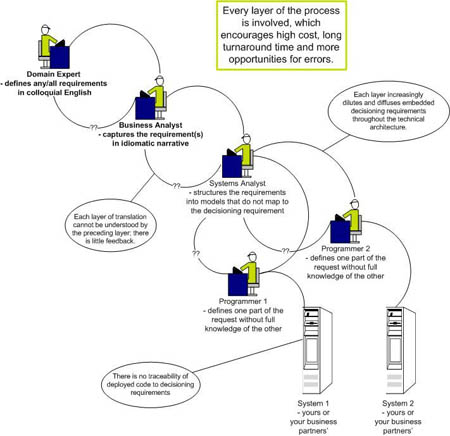
The business user(s) may think they have described clear and explicit decision specifications. But when they seek to reuse or redefine them, they are usually dismayed to find that this requires reprocessing through all stages of translation and elaboration as if they were building an entirely new requirement, with the additional burden of accounting for the existing implementation. This is a root cause of the pervasive disconnect between business and IT -- the gap caused by multiple layers of translation and dilution that loses the identity and integrity of the original decision specification. Therefore, we suggest a new approach as shown in Figure 2.
Figure 2 Systems Development Lifecycle: "The New Way"
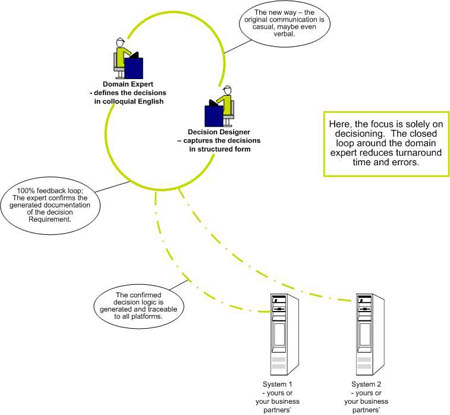
Decision Analysis
Getting Started
The above discussion has suggested that data is peer with decisioning -- so which comes first, the 'data egg' or the 'decisioning chicken'?
Actually, we have already defined the 'egg' -- the business derives value or achieves its purpose by changing the state of primary business objects, whether they be insurance policies, loan accounts, patients, trains, or any other object of value. These primary business objects are the 'eggs' for both data and decisioning; we must start by discovering these primary objects from original sources. They are usually self-evident, and a cursory review of strategy documentation will highlight and clarify any ambiguities. But if the primary objects cannot be defined quickly (minutes, not days) and with certainty, the business should not be building a system -- it has much bigger issues to worry about!
The primary business object is by definition both tangible and discrete; therefore, it can be uniquely identified. Also by definition, it will be a source of value for the business and so the business will assign a unique identifier to it -- its first data attribute. In fact, a simple litmus test for these objects is to look for proprietary and unique identifiers assigned by the business (even in manual systems).
Because it exists and generates value, external parties may also be involved and cause us to add specific additional attributes for interface or compliance purposes (e.g., an IRS number), and we might also add other identifying attributes to ensure that the primary object can be uniquely found using 'real world' data. So there is a small set of data that can be found and modeled simply because the primary object exists; this set of data is generic and will be more or less common across all like businesses. Therefore, it cannot be a source of business differentiation.
So what other data is there that will allow us to differentiate our business? The amount of data that we could collect on any given topic is huge -- how do we determine what additional data is relevant?
Decisioning! How we make decisions is the key differentiator of any business -- how we decide to accept customers, approve sales, price sales, agree terms and conditions, etc. The important additional data will now be found because it is needed for decision making.
We are now ready to do decision analysis; that is, after the initial data scoping, and prior to either detailed data or process analysis.
Decision Discovery
Decision analysis is both simple and intuitive because this is the primary activity of the business -- this is what the business knows best.
A decision is a single atomic value -- we cannot have half a decision any more than we can have half an attribute. So we are looking for explicit single-valued outcomes, each of which will be captured as a new data attribute.
Let's start with our business object (say, 'insurance policy'), and with a state change that will cause a change in the value of that object (say, 'approve insurance policy'). Now we need to access the domain expert within the business. The domain expert is the one who can readily answer the question: What decisions do you make in order to ... approve this insurance policy?
There is a pattern to most commercial decision making that helps structure the decision discovery process.
Figure 3. The Decision Sequence
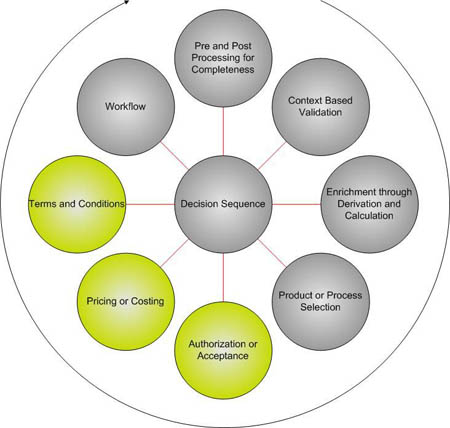
The green circles are the most important in the cycle. We can start analysis with the first of the primary (green) decisions ('Authorization or Acceptance' in the above Figure 3) -- these are the 'will I or won't I' decisions. For our insurance policy, 'will I or won't I' accept this risk? (simply replace the business object and state for other domains as required; e.g., for a hospital, 'will I or won't I admit this patient?', etc.). Determining this decision may identify many precursor decisions that need to be considered first. For instance, for our underwriting question we might need to ask:
- What is the inherent risk of the object?
- What is the customer risk?
- What is the geographic risk?
These decisions in turn may give rise to further decisions so that we develop a tree of decisions -- this is the decision model for authorization.
Now we can move on to the next in the primary class of decisions: At what price? (or cost if a cost centre) -- see 'Pricing or Costing' (Figure 3). In this case, the question is 'what decisions do you make to determine the price . . . of this risk? ' Again, this may result in a tree of decisions (for instance, pricing based on various optional covers, pricing for the different elements of risk, channel pricing, campaigns and packages, etc.).
Following "At what price?" we can repeat the process for the 'Terms and Conditions' and then the other pre- and post-decisions:
- Pre-Processing Check: Do I have sufficient information to start decision
making?
- Context Based Validation: Is the supplied data valid?
- Enrichment: What further data can I derive to assist with the primary decision
making?
- Product or Process Selection: Do I need to determine one decision path from other possible paths for the primary decision making?
And after the primary decision making ...
- Workflow: Now that I have made my primary decisions, what do I need to
do next?
- Post-Processing: Am I finished and complete without errors? Are my decisions within acceptable boundaries?
Normalization
Data normalization is a semi-rigorous method for modeling the relationships between atomic data elements. It is 'semi-rigorous' because normalization is a rigorous process that is dependent on several very non-rigorous inputs, including:
- Scope: determines what is relevant -- we don't normalize what is not in
scope.
- Context: determines how we view (and therefore how we define) each datum.
- Definition of each datum: this is highly subjective yet drives the normalization process.
Data normalization is based on making a number of subjective assertions about the meaning and relevance of data, and then using the normal forms to organize those assertions into a single coherent model.
Normalization with regards to decisions is similar. Each decision derives exactly one datum, and is 'atomic' in the same way that data is.
Similarly, each decision has relationships to the other decisions in the model. The decisions are related by both sequence and context. In this regard, context plays a similar role to the 'primary key' in data normalization. Some of the inter-decision relationships include:
- All decisions have a data context that is derived from the normalized placement
of its output datum.
- Each decision definition may precede and/or follow exactly one other decision
definition.
- Each decision belongs to the group of decisions that share the same context.
- In a direct parallel of 4th normal form, unlike decisions that share context
should be separately grouped.
- A group of decisions itself has sequence and may also be grouped with other decisions and groups according to shared context.
Further Analysis
We have now defined the core analysis approach. This section now looks at some guidelines for extending the analysis. The 'who, what, why, where, when, how' framework is one possible framework that can help. We have already discussed two of the elements:
- What: The object that has state.
- How: The decision process that determines the change of state.
Now try to address the rest of the framework. Question whether decisions need to adapt to any of the following:
- When: The nature of the events that stimulate state change -- "Will
I admit this patient differently in an emergency vs non-emergency?"
- Where: Are there any jurisdictional or local elements to the state change
-- "Will I accept this business if it is in a war zone?"
- Who: Who is making the state change -- "Is a broker transaction handled
differently to an internal transaction?"
- Why: Why is this state change important to the business -- especially, how is it valued?
All elements of the above should be considered and factored into the overall decision model to produce a robust and complete decision design.
Decision Driven Data Design
Figure 4. Decision-centric Development
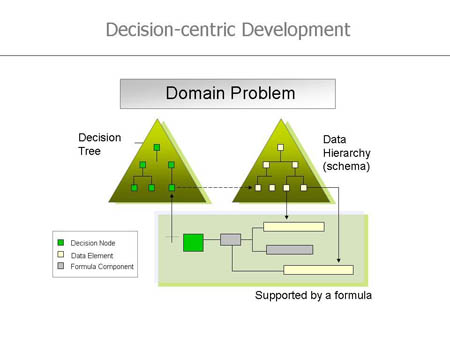
We have suggested that decision and data models are peer design artifacts. Following the initial discovery and elaboration of the primary business objects, we worked through the decision discovery process, which in turn identified new data attributes (the decision outputs). If we locate the decisions around the data constructs, we can build an integrated decision/data model (represented by the two triangles in Figure 4). This combined model is self-validating and improves the overall rigor of the analysis.
Following the discovery of the decisions, we can then elaborate them with formulas. Formulas provide additional detail regarding the consumption of data by decisions, thereby driving further demand for data. If the system cannot provide this data, then by definition the business cannot make the decision and the process cannot continue.
In this way, decisioning can be shown to define the scope and context of the data, which then compounds with the decision usage to arrive at the data definition, which in turn drives the normalization and modeling processes for both.
Note that the data models used in decision modeling are subsets of the domain data model -- they need to contain only the data required by the decisioning that is currently in focus. They are, in effect, normalized models of data transactions rather than a model of the entire business. The XML schema standard is a useful standard for describing normalized transactional data.
These transactional views can be easily overlaid onto the business object model to synthesize a more complete domain model. This model will only contain the data actually required by the business -- there is no second guessing of the data requirements as often occurs in a traditional approach, with significant cost implications.
Decision Driven Process Design
Decisioning also drives process. For the decision to execute, the decision must be supplied with its precursor data by a process. This data, and therefore the process, cannot be defined until the decision requirements are known. Then, for the decision to have any effect, a process must implement some response. While it is possible to define and build processes in anticipation of the decisioning that will drive them, it is sensible to analyze the decisioning in order to determine the range of inputs and outcomes, and then to normalize the process responses to them.
Handover and the SDLC
We can achieve a verified and tested decision model, and its integrated and co-dependent data design, with relatively modest effort. No system design or coding is required to this point. Most architectural and design options remain open -- at this stage even platform is irrelevant. We have, in fact, defined and constructed the core functionality of the system from the business's perspective without constraining the technology options. Even better, we can retain the identity of this core functionality over the long term, even across multiple implementations -- there need never be another legacy system.
Implementation is now of little interest to those business users who are responsible for decisioning -- we have a clear and well-defined handover point. It is feasible, even desirable, to simply hand over the decision model and data schemas to systems designers as their starting point. This highlights a critical point: Decision analysis belongs in the inception phase of traditional SDLC's, or precedes it entirely. By definition the subsequent system design must be able to supply and receive data that complies with the decisioning schemas. And the system must provide appropriate process responses to the decisions made. While these processes remain undefined, this is secondary analysis and is tightly bounded by the decisioning design that precedes it; therefore, it is of comparatively low risk.
The traditional systems development cycle is then used to design, build, and/or reuse as appropriate to support the decisioning requirements. It is the developer's task to provide an infrastructure within which the decisioning can occur.
Resources
The Tools
With the correct tools, the above decision discovery process can be fast and efficient.
How do we choose the correct tool?
First, do not choose one that relies on narrative or colloquial language to describe the requirement!
The problem here is not the tool but the use of language. A dearth of structured rule writing standards means that decision definition is almost always reduced to a series of personal idioms -- local phrases that have only very local, even personal, meaning. Every practitioner finds their own decision writing style, and even that changes over time, often within a single document.
English is highly nuanced; ambiguity and imprecision are typical and endemic. When compounded with personal writing styles, our experience is that the majority of decision declarations are imprecise, no matter how careful the author.
Therefore a consequence of capturing decisions in narrative is to create a new class of analysis problem for the downstream developer -- analyzing the narrative version of the decision model. And because it is a personal abstraction, there will be misinterpretations (if you are lucky you might find some of these in testing, but only after significant downstream cost). And there is a further subtle trap here. The business analyst who produces the narrative usually considers their ('more important') job to be done; it is now over to the developer to get it right. Similarly, the developer resents that they have to re-analyze the narrative, and that this is impacting on their (also 'more important') job. The perception gap can be debilitating!
So what sort of tool do we want?
- It must be definitive. Every fact, every operator, must be clear and explicit
so that the elements of the decision model are guaranteed to be unambiguous.
- It must be structured. The construction of elements into a semantic model
must be managed to ensure that only one possible interpretation (and therefore execution)
path is possible given any specific problem instance.
- It must be easy to use. It should be faster than writing the equivalent
narrative -- using graphical modeling if possible.
- It must produce business accessible output for verification. The decision
analyst should be able to close the loop with domain experts by hands-on guided walkthrough
and confirmation of the decision constructs before expensive downstream work is undertaken.
- It must be testable. The decision models should demonstrate correct results
before expensive downstream work is undertaken. Only after this point can we
be sure that the decision requirements are known and complete, removing much of the
risk and cost of the following traditional SDLC approaches.
- It must require no 'fingerprints' to achieve executable code. We do not want verified and tested decision models to be hand-cranked into code, which would undo all verification and testing by definition.
The People
Who should perform decision analysis? Anyone who has:
- Lateral thinking and analysis skills -- to understand the decision constructs
within verbatim, unstructured decision knowledge from domain experts.
- Structured, focused thinking -- to transform verbatim, unstructured decision knowledge from domain experts into normalized and structured decision and data models.
But of course it is not that simple! Most people come with some history that will affect their analysis behavior. Here are some possible 'gotchas' for the more traditional roles:
Software Developers who:
- Apportion decisions across their existing technical design, thereby destroying
the integrity of the 'decision model' as understood by the business.
- Mentally transform logic into code, and then redundantly (in their mind) record
the presumed coded form as the decision; this is often preceded by actually turning
it into code ("It was easier to write it as code" followed by "It
was only 35 lines of C++").
- Think in terms of systems. Systems deal with an order of magnitude more
complexity than do decision models. It is the simplicity and purity of the
decision model that the business seeks, and which we lose when we analyze decisions
in terms of the rest of the system.
- See the system as the objective. We want the decisioning to drive the system
design and operation, not the other way around. The system exists to implement
decisioning -- it has no other purpose!
- Resent the idea of generated code ('I could do it better!'), thereby missing the point that it is not the quality of the code but the intervention of the developer that is the problem.
Business Analysts who:
- Have developed personal styles of output that involve narrative storytelling
and considerable attention to context at the expense of verifiable detail -- the
'artist' who produces large, well-considered narrative style documents that must
themselves be subject to analysis.
- Disagree that analysis outputs should be verifiable and testable. Traditional
requirements definitions are not easily testable -- and narrative especially cannot
be tested. If it's not tested, how do we know it is complete, or even consistent!
- Are wedded to traditional approaches. Decisions are not the traditional
focus of business analysis, which usually sees them as properties of data or process,
and a significant paradigm change is required to invert this traditional relationship.
- Are wedded to traditional approaches. Decisions are not the traditional
focus of business analysis, which usually sees them as properties of data or process,
and a significant paradigm change is required to invert this traditional relationship.
- Resent being 'technical' as implied by the need to define, normalize and test. But the analysis output must be normalized; both decisions and data must be defined once, and only once, into an exact and correct context. Without this purity, the requirements cannot be shown to be complete or consistent.
There are some additional characteristics that are helpful to the Decision Designer.
- Domain knowledge and general business knowledge. The more the better.
- Normalization skills. It is essential to understand normalization and how
to apply it to both data and decision modeling.
- Ability to move easily from broad concept to minute detail (core object to logical
operation).
- Perseverance with detail. They should test their own decision models in
detail -- this aids understanding and avoids handover costs. The decision modeler
tests because it helps them to understand both the problem and their solution!
- Communication skills. The decision analyst is the key interface between
the domain expert and the system. They are primarily a business representative
dressed in analysts clothing.
- Logic. They need to be logical but it is better if they do NOT know how to code in traditional development languages! We only want the logic -- not all the rest of the dressing that comes with these languages.
CONCLUSION
In this Part One, we have defined decisioning and put forward the idea that it is a practical and valuable new design approach for IT. We will build on this concept in Part Two,[3] where we outline that decisioning has a direct and strategic importance to the business itself.
We will illustrate that the decisioning approach is focused on the core objects of the business (what is traded, managed, leveraged, used, built, or sold in order to achieve the objectives of the business), and we can give these objects a more common name: products.
Part Two provides more detail on this concept and how decisioning is, in fact, the primary differentiator of like (non-commodity) products.
Notes and References
[1] The Object Management Group (OMG) is a non-profit computer
industry specifications consortium. Its members define and maintain the Unified
Modeling Language (UML). The UML is the OMG's most-used specification, applying
to application structure, behavior, and architecture, as well as business process
and data structure. OMG's UML v1.5, Section 3.22.3 appears to exclude the entire
class of business rules from the methodology: "Additional compartments
may be supplied as a tool extension to show other pre-defined or user defined model
properties (for example to show business rules ...) ... but UML does not define them..." ![]()
[2] Capers Jones. Applied Software Measurement: Assuring
Productivity and Quality. McGraw-Hill (1996). ![]()
[3] Mark Norton, "Decisioning: A New Approach
to Systems Development (Part 2)," Business Rules Journal, Vol. 8, No. 1
(Jan. 2007), URL: http://www.BRCommunity.com/a2007/n326b.html ![]()
# # #
Standard citation for this article:
About our Contributor:

")









Online Interactive Training Series
In response to a great many requests, Business Rule Solutions now offers at-a-distance learning options. No travel, no backlogs, no hassles. Same great instructors, but with schedules, content and pricing designed to meet the special needs of busy professionals.